

こんにちは。ジェネレーションB、運営者のTAKUです。
AIの個人情報リスクって、ここ気になりますよね。
生成AI個人情報入力をどこまでやっていいのか、ChatGPT個人情報は大丈夫?と不安になったり、個人情報入力NG例を探して「結局なにが危ないの?」となりがちです。
この記事では、要配慮個人情報の扱いから、AI学習データとオプトアウト、生成AIログ保存期間と設定、生成AI個人情報保護法の論点(第三者提供や越境移転の考え方)まで、ひと通り“迷わない形”に整理します。
さらに、生成AI社内ルールテンプレ、DLP、マスキング、匿名化、仮名化、RAG運用で起きがちなプロンプトインジェクションや過剰共有もまとめて扱います。
あなたが今日から取れる対策まで落とし込むので、安心して読んでください。
結論から言うと、AIって「入れた情報を増幅して扱いやすくする」道具なんですよ。
便利さの裏側に、個人情報や機密の取り扱いが追いつかないと事故が起きやすい。
なのでこの記事は、怖がらせるためじゃなくて、あなたが安心して使い倒すための地図にします。

この記事でわかること
- AIに入力していい情報とNG情報の考え方
- 学習される可能性とオプトアウトの要点
- 個人情報保護法で注意するポイント
- 企業で事故を減らす運用と技術対策
1. AIの個人情報リスク入門
まずは「何が個人情報で、どこからが危険なのか」を土台から押さえます。
ここを曖昧にしたまま使うと、設定やルールを頑張っても事故が起きやすいんですよ。
ここでのゴールはシンプルで、「迷ったらこの判断軸で決められる状態」にすることです。
細かい例外より、まずは事故が起きにくい型を作りましょう。
1-1. 個人情報と要配慮個人情報
AIの個人情報リスクを考えるとき、最初にやるべきは言葉の整理です。
個人情報は、氏名や住所みたいな“直球”だけじゃありません。
組み合わせると個人が特定できる情報も含まれます。
たとえば、部署名+役職+具体的な出来事+日付、みたいなセットは要注意です。
そして特に慎重に扱いたいのが要配慮個人情報です。
医療・健康、障害、犯罪被害など、取り扱いを間違えると本人の不利益につながりやすい領域ですね。
生成AIに相談したい気持ちは分かるんですが、ここは入力前に一段ブレーキを踏むのが安全です。
私の結論
AIを便利に使うほど、情報は「具体→抽象」に寄せた方がうまくいきます。
個人が特定できる要素を削るだけで、やりたい作業(文章の改善、要約、企画の壁打ち)はだいたい成立します。
個人情報が“増える”ポイントを押さえる
ここ、地味に大事なんですが、AIは「情報を勝手に作る」だけじゃなくて、散らばった情報をまとめて、読みやすく、使いやすくするのが得意です。
つまり、もともと断片的で見えにくかった個人情報が、AIの要約や整理によって“見えやすくなる”んですよね。
これがリスクの正体のひとつです。
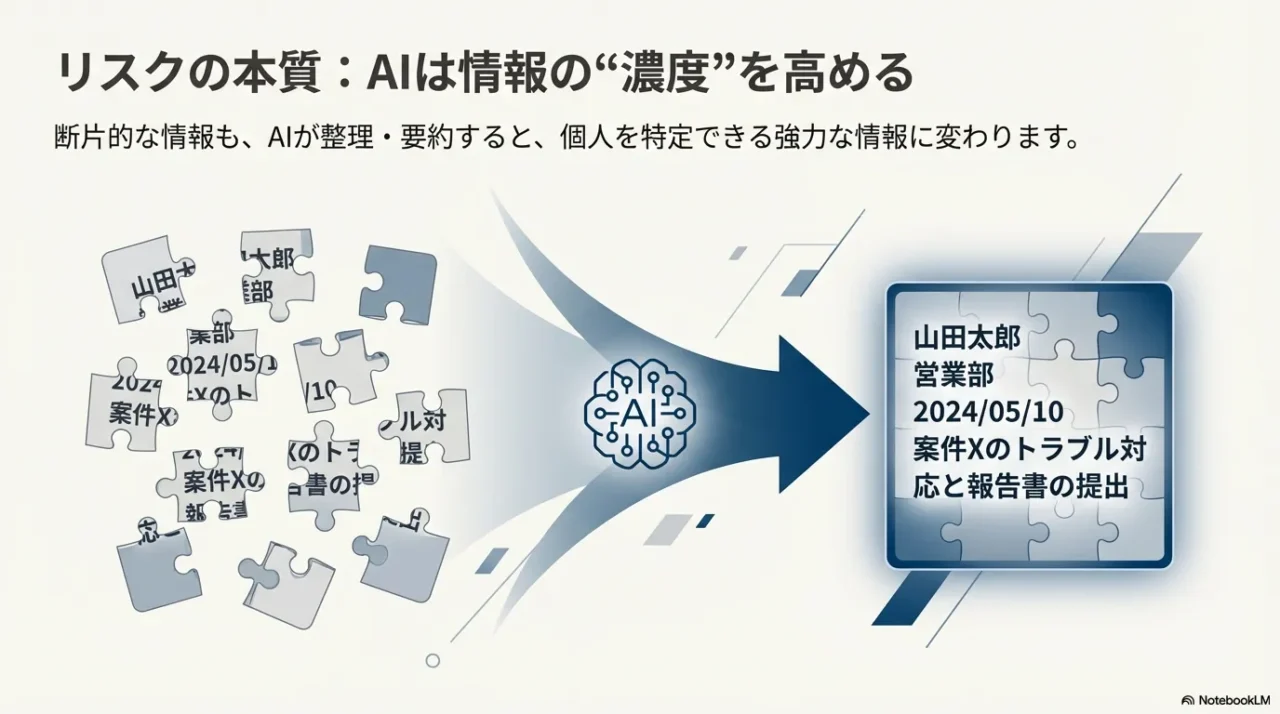
例えば、社内のやり取りの断片をAIに投げて「経緯をまとめて」と頼むと、関係者名、顧客、時系列、決裁者、トラブル内容が一気にまとまります。
便利なんですが、同時に「そのまとめ」が漏れたら被害が大きい。
あなたがやりたいのは要約でも、結果として個人情報の“濃度”が上がることがあります。
要配慮個人情報っぽい相談が来たらどうする?
個人で使っていると、健康、メンタル、家庭の事情などをAIに相談したくなること、ありますよね。
気持ちはめちゃくちゃ分かります。
だから私は、完全にやめろとは言いません。
その代わり、本人特定につながる要素を落としてから相談するのが現実的かなと思っています。
- 年齢や居住地は「30代」「地方」くらいに丸める
- 病院名、会社名、学校名、担当医などは出さない
- 症状の固有性が高い場合は、一般化して相談する
迷ったときの判断軸
- 特定できるか:これ単体、または組み合わせで個人が浮かぶか
- 漏れたら困るか:第三者に見られたら人生・仕事に影響があるか
- 目的に必要か:その情報がないとAIが役に立たないか
- 代替できるか:仮名化や抽象化で同じ成果が出せるか
この判断軸で「うーん」と迷うなら、だいたい入力しない方が安全です。
AIは万能じゃないので、入力を減らしてもちゃんと役に立つ場面が多いですよ。
1-2. 生成AI個人情報入力NG例
生成AI個人情報入力で一番わかりやすいのは、「入力しないほうがいいもの」を先に決めることです。
ここが曖昧だと、誰かが善意でコピペしてしまいます。
現場で使える3段階(OK/マスク/禁止)にすると運用が回ります。

| 区分 | 代表例 | 考え方 |
|---|---|---|
| OK | 公開情報、一般論、匿名の文章 | 個人が特定できず、社外に出ても困らない範囲 |
| マスク | 顧客名、案件名、社内固有名詞 | 顧客A、案件X、役割名などに仮名化して目的を達成 |
| 禁止 | 氏名、住所、電話、メール、口座、マイナンバー、ID/パスワード、身分証、医療/病歴 | 個人情報入力NG例の中心。漏えい時の影響が大きすぎる |
ポイントは、禁止を増やしすぎないことです。
禁止だらけだと現場は使わなくなります。
逆に「マスクOK」を広く取ると、効率と安全のバランスが取りやすいですよ。
NGになりやすい“素材”もまとめて押さえる
「氏名・住所はダメ」は分かりやすいんですが、現場で事故が起きやすいのは文書そのものです。
たとえば、契約書、請求書、顧客リスト、履歴書、医療系の書類、面談記録。
こういうのを“丸ごと”貼るのが一番危ないです。
コピペ事故を止めても、最後に残るのが“紙”です。
紙の出口を固めると漏えい確率が一段下がります。

 | 価格:117999円 |

コピペ事故が多い素材(まずはここを封じるのがおすすめ)
| 素材 | なぜ危ない? | 代替案 |
|---|---|---|
| 顧客リスト・名簿 | 個人データが集中している | 属性だけを集計して相談する |
| 履歴書・職務経歴書 | 学歴・経歴・連絡先が一式 | 固有名詞を仮名化して添削する |
| 医療・健康の記録 | 要配慮個人情報に触れやすい | 一般化して質問し、具体情報は入れない |
| 契約書・請求書 | 取引先・金額・条件が含まれる | 条項の構造だけ抜き出して質問する |
| チャットログ・通話文字起こし | 関係者の会話がそのまま残る | 要点だけを自分で要約してから投げる |
“入力しない”を守っても、社内には残さざるを得ない原本があります。
保管の物理リスクも一緒に潰しましょう。

マスク前提の“安全な依頼文テンプレ”
私は、AIに投げる前に「置換」を先にやります。
これだけで事故率が下がるし、心理的にもラクですよ。
例えばこんな感じ。
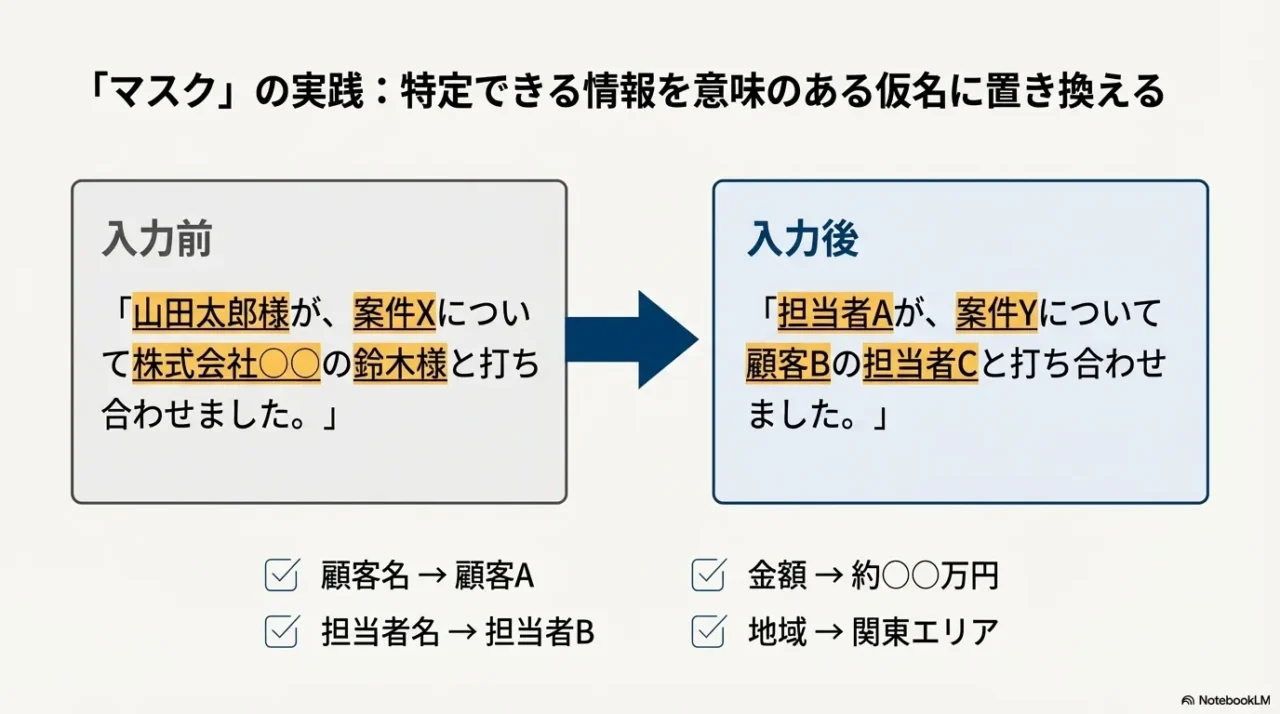
置換テンプレの例
この“ひと手間”が面倒に見えるんですが、慣れると数十秒でできます。
AIに頼むのは速いのに、入力の準備が雑だと事故も速い。
ここ、気をつけたいところです。
1-3. ChatGPTの個人情報は大丈夫?
ChatGPTの個人情報は大丈夫?に対して、私の答えは「条件次第」です。
AIサービスは、プランや設定、組織契約、データ取り扱いポリシーで前提が変わります。
だから、ひとつの断言は危ないんですよね。
最低限ここだけ確認
- 入力内容がモデル改善に使われる設定になっていないか
- 履歴やログの扱い(保存期間や削除導線)がどうなっているか
- 業務利用なら法人向けの契約・管理機能があるか
注意
無料の個人アカウントに、仕事の顧客情報や契約書原文を入れるのは避けた方がいいです。境界を分けるだけで事故確率がガクッと下がります。
比較や選び方まで含めて整理したいなら、私がまとめた下の記事も参考になると思います。
結局どこが怖い?を分解すると見える
不安の正体って、だいたいこの3つに分かれます。
- 入力が残る不安:履歴、ログ、共有リンク、連携先に残る
- 入力が使われる不安:学習や改善に回るのか、どこまで匿名化されるのか
- 出力が漏れる不安:自分が共有してしまう、社内で拡散してしまう
この中で、私が一番現実的に怖いと思うのは「自分が共有してしまう」系です。
AIの画面をスクショして社外に送る、議事録に貼る、関係者が多いチャットに転送する。
ここが一番起きます。
だから、ツール選びよりも、共有の作法を先に決めた方が守りやすいんですよ。
私がやってる“3分セルフ監査”
個人でもできるチェック
- いまの依頼文に、固有名詞(人・会社・場所・ID)が入ってないか
- 入っているなら、仮名化しても同じ目的を達成できるか
- 履歴に残って困る内容ではないか
- この回答を誰かに転送する未来はあるか

これをやるだけで、ほとんどの“うっかり”は防げます。
AIって気軽に使える分、気軽に事故ります。
だからこそ、軽いチェックを習慣化するのが一番コスパいいですよ。
1-4. AI学習データとオプトアウト
AI学習データとオプトアウトの話は、誤解が多いところです。
ざっくり言うと、問題は2つに分かれます。
- 学習:入力がモデル改善に使われるかどうか
- ログ:品質改善や不正利用対策として、一定期間残る可能性
ここが分かれているサービスも多いので、「オプトアウトしたから全部消える」とは限りません。
だから私は、入力を小さくする(データ最小化)+設定でリスクを下げる(データコントロール)の二段構えにしています。
個人ユーザー向け:今すぐできるデータコントロール
- モデル改善への提供設定があるならオフにする
- 履歴を残さない運用に切り替える(必要な場合だけ)
- プロンプトは固有名詞を仮名化してから投入する
- 不安がある用途は、先に要約して抽象度を上げてから依頼する
オプトアウトで“ゼロ”にならない理由
ここ、気になりますよね。
オプトアウトは多くの場合「モデル改善に使わない」方向の設定です。
一方で、サービス運用上のログ(不正利用の監視、障害解析、品質改善)は残り得る。
だから私は、オプトアウトの有無に関係なく、最初から入れ方を整えます。
私の感覚だと、オプトアウトは“最後の保険”です。
保険があるから無茶する、ではなく、そもそも事故りにくい運転をして、その上で保険も入る。
これが一番ラクです。
目的別に、入れがちな情報を安全に置き換える
目的は同じでも、材料は変えられる
| やりたいこと | 入れがちな情報 | 安全な代替 |
|---|---|---|
| メールの添削 | 宛名・会社名・署名 | 顧客A、担当者B、部署名は一般化 |
| 議事録の要約 | 参加者名・顧客名・時刻 | 役割名に置換、固有名詞は削除 |
| 契約条項の理解 | 契約書原文 | 条項の要点だけ抜粋し、固有情報は除外 |
| 採用面接の振り返り | 候補者の詳細 | スキル要件と評価軸だけで相談 |
こういう置換ができると、AIは一気に“安全な相棒”になります。
逆に言うと、入力の作法がないまま使うと、AIは“危ない拡声器”になります。
どっちにするかは、使い方次第ですよ。
1-5. 生成AIログ保存期間と設定
生成AIログ保存期間と設定は、サービスや契約形態でかなり差が出ます。
一般論としては、品質改善や不正利用検知の目的で一定期間ログが保持されることがあり、期間は短いものから長いものまで幅があります。
なので、私は「期間を当てにしない」運用に寄せます。
つまり、保存期間が短くても、そもそも入れなければリスクは出ない。
ここが一番強いです。
目安の考え方
サービスの仕様変更もありえるので、業務利用では契約条件・管理画面・運用ルールの3点で確認しておくと安心です。
設定だけで安心しないコツ
設定は大事なんですが、最後は運用です。
入力担当が変わった瞬間に崩れるケースが多いので、次の2つはセットにしておくのがおすすめです。
- 入力OK/マスク/禁止の例を社内で共有する
- コピペ前にチェックする簡易手順を作る
ログが残る場所は“本体”だけじゃない
生成AIログ保存期間と設定って、つい「チャット画面の履歴」だけを見がちなんですが、実際には周辺にログが残ることがあります。
ここが落とし穴です。
- ブラウザの自動入力、クリップボード履歴、拡張機能
- 共有リンクや共有フォルダに置いた生成物
- 連携機能(メール、ドライブ、社内Wiki)を使ったときの参照履歴
- 社内のプロキシやセキュリティ製品の監査ログ
“置いた瞬間にリスクが増える”なら、置き場所そのものを暗号化しておくのが早いです。

 | 価格:74950円 |
つまり「AI側の設定をオフにしたから安全」ではなく、自分の操作と周辺環境も含めて管理する必要があります。
ここ、ちょっと面倒ですが、逆に言えば押さえるポイントが見えると怖くなくなります。
私が推す運用ルール
- 個人情報や機密を扱う用途は、最初からAIに投げない
- 投げるなら、仮名化・要約・抽象化を先にやる
- 生成物を共有するときは、宛先と権限を必ず確認する
- チーム利用は「誰が何を入れていいか」を明文化する
設定は“仕組み”で、運用は“習慣”です。
習慣ができると、AIの個人情報リスクはぐっと下がりますよ。
1-6. 生成AI個人情報保護法の論点
生成AI個人情報保護法の論点は、ざっくり言うと「本人の権利を守るために、取り扱いをコントロールできているか」です。
特に気になるのは、目的外利用、第三者提供、越境移転、漏えい時の対応あたりですね。
重要
迷いやすいポイント
- 本人同意:どんな目的で使うのか、範囲は適切か
- 委託:外部サービスに処理させる場合の管理・監督
- 漏えい報告:発生時に何を確認し、どう連絡するか
私のおすすめは、法律の条文を追いかける前に「自社の情報分類」と「入力禁止」を先に固めることです。
実務の事故は、だいたい入力から始まります。
生成AIで“起きやすい論点”を実務目線で整理
法律の話って、読むほど難しく見えますよね。
でも実務では「データがどこへ流れて、誰が扱って、何の目的で使われるのか」を整理できれば、だいたい見えてきます。
実務での整理フロー
- どんな業務で生成AIを使うのか(利用目的)
- プロンプトや参照データに個人情報が入るのか(入力の有無)
- 入るなら、仮名化・匿名化・マスキングで減らせるか(データ最小化)
- 外部サービスに送る扱いになるか(委託・第三者提供の可能性)
- 国外で保管・処理される可能性はあるか(越境移転)
- 事故が起きた場合の窓口と手順があるか(漏えい対応)
このフローで「ここ怪しいかも」と思ったところが、法務・情シス・専門家に相談すべきポイントです。
逆に言うと、ここさえ整理できれば、相談もスムーズになります。
(出典:個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」)
“断定しない”のが安全な書き方
この記事でも繰り返しますが、生成AIの仕様や契約条件は変わることがありますし、取り扱う情報の種類や業務フローでも結論が変わります。
だから、私は「絶対OK」「絶対NG」を乱発しません。
その代わり、判断軸と代替策を示す。これが現場で一番役に立ちます。
2. 企業のAI個人情報リスク対策
ここからは企業のAI個人情報リスク対策です。
ポイントは「ルールだけ」でも「技術だけ」でも足りないこと。
ガバナンス×技術×教育の三点セットで、事故の芽を潰します。
“技術で事故を減らす”を一発で体感しやすいのが、社内の出入口をまとめて守るUTMです。

 | 【UTMルーター 中古】ライセンス2027年迄 FortiGate 60F Fortinet ギガビット対応 VPN 小規模オフィス向け 高速モデル FG-60F ACアダプター付属 初期化済み 価格:40000円 |
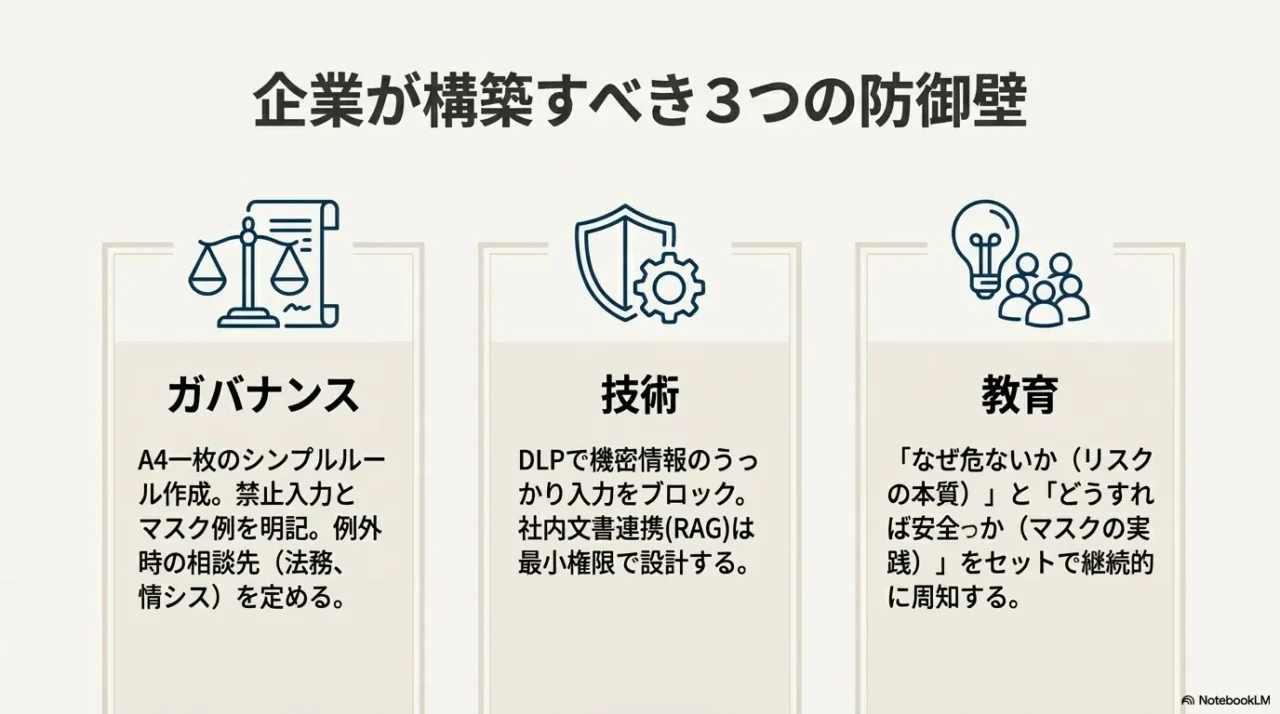
個人の工夫だけで守り切るのは限界があるので、会社で使うなら仕組みに寄せるのが正解です。
現場に丸投げすると、だいたいどこかで崩れます。
2-1. 生成AI社内ルールテンプレ例
生成AI社内ルールテンプレは、難しく作る必要はありません。
むしろ短いほうが守られます。私なら、まずA4一枚に落とします。
A4一枚で作る社内ルールの骨格
- 目的:何の業務で使うか(例:文章整形、要約、アイデア出し)
- 禁止入力:個人情報入力NG例を列挙(要配慮個人情報も明記)
- マスク方法:仮名化のルール(顧客A、案件X、約◯◯)
- 承認フロー:例外時の相談先(法務、情シス、上長)
- ログと監査:誰が、いつ、何を扱ったか(できる範囲で)
さらに運用を回すなら、禁止より「マスク例」を充実させるのが効きます。
現場は例があると迷わなくなります。
ルールが守られない“ありがちな理由”を潰す
社内ルールって作るだけなら簡単なんですが、問題は「守られない」ことです。
守られない理由はだいたい同じで、面倒、分からない、例外が多いの3つ。
だからテンプレには、例外を吸収する仕組みを入れます。
例外を吸収する小ワザ
- 例外は「相談先」を決めるだけでOKにする(法務・情シス・管理者)
- マスク例を3〜5個、業務ごとに用意する
- 禁止入力は“素材名”で書く(顧客リスト、契約書原文など)
役割分担の例
| 役割 | やること | よくある落とし穴 |
|---|---|---|
| 現場 | 仮名化・マスクの徹底、最終確認 | 急ぎでコピペしてしまう |
| 管理者 | 運用ルール更新、教育、例外判断 | ルールが古いまま放置 |
| 情シス | DLP、権限、ログ、環境整備 | 現場の実態と乖離する |
| 法務 | 契約・同意・委託先管理の整理 | 運用に落とし込まれない |
こうやって、ルールを「読み物」じゃなく「使い方」にすると、定着しやすいです。
社内のAI活用を伸ばしたいなら、ここが勝負どころですよ。
2-2. 第三者提供と越境移転と委託
第三者提供と越境移転と委託は、生成AIの法務チェックで必ず出てくるテーマです。
ただ、言葉が難しくて止まりがちなので、私は「何が起きると該当しそうか」だけ押さえる派です。
ざっくり整理(実務の見え方)
| 論点 | ざっくりイメージ | 実務での打ち手 |
|---|---|---|
| 委託 | 外部サービスに処理を任せる | 委託先管理、契約、権限、ログ |
| 第三者提供 | 別の主体へ渡る扱いになり得る | 提供範囲の最小化、同意・手続き確認 |
| 越境移転 | 国外にデータが渡る/保管される可能性 | 保管場所・処理場所・再委託の確認 |
ここは契約と運用の世界です。
サービスの仕様や契約は更新されることもあるので、社内で判断が必要なときは、法務や専門家と一緒に進めるのが安心です。
ベンダー確認は“質問リスト”にすると強い
第三者提供と越境移転と委託って、概念を理解するより、実際には「ベンダーに何を聞くか」が大事です。
私なら、次の質問を用意します。
これがあると、現場と法務の会話が一気に噛み合います。
ベンダーチェックの質問例
- 入力データはモデル改善に使われるのか、設定で制御できるのか
- ログは何の目的で保持され、どこに保管されるのか
- 再委託先(サブプロセッサ)はいるのか、管理方法はどうか
- 国外で処理・保管される可能性はあるのか
- 削除要請や監査対応の窓口はあるのか
- インシデントが起きた場合の通知条件と期限はどうか
この質問に明確に答えられないベンダーは、業務利用だと怖いです。
逆に、答えが整理されているなら、社内でも判断しやすくなります。
2-3. DLPとマスキング匿名化仮名化
DLPとマスキング匿名化仮名化は、「入力しない」を徹底できないときの現実解です。
特に企業だと、要約や改善のために“それっぽい素材”を入れたい場面が出ますよね。
それぞれの役割
- DLP:機密パターン(番号、個人情報っぽい文字列)を検知してブロックする
- マスキング:黒塗り・伏字・置換で「意味は保ちつつ特定要素を消す」
- 仮名化:顧客A、担当者B、案件Xのように置き換え、再特定リスクを下げる
- 匿名化:個人を識別できない状態を目指す(ただし再特定の落とし穴に注意)
マスキング例(コピペで使える)
- 顧客名:株式会社◯◯ → 顧客A
- 担当者:山田太郎 → 担当者B
- 金額:1,234,567円 → 約120万円、または売上比率だけ
- 住所:東京都◯◯区… → 関東エリア
Google系のDLPや管理の考え方をもう少し知りたい場合は、Gmail連携の文脈ですが、下の記事も参考になるはずです。

匿名化は“やったつもり”が一番危ない
匿名化って言葉は強いんですが、実務では「匿名化できたと思ったのに、実は再特定できた」が起きがちです。
例えば、役職が特殊、担当領域が狭い、出来事がニュースになっている、などがあると、名前を消しても人が浮かびます。
だから私は、匿名化をゴールにしないで、仮名化+データ最小化を基本にします。
必要な情報だけ残して、特定要素は消す。これが一番現実的です。
手段ごとの効き方
| 手段 | 得意なこと | 注意点 |
|---|---|---|
| DLP | うっかり入力を止める | パターン外の個人情報はすり抜ける |
| マスキング | すぐ実装できる | 置換漏れがあると意味が薄れる |
| 仮名化 | 意味を保ったまま特定要素を消す | 対応表を作ると再特定のリスクが残る |
| 匿名化 | 個人が識別できない状態を目指す | 組み合わせで再特定されることがある |
技術は魔法じゃないので、「入力を小さくする」運用とセットで効かせるのがコツです。
これができると、社内でも安心して活用が広がります。
2-4. RAGと過剰共有とプロンプトインジェクション
RAGは、社内ドキュメントやナレッジを検索して回答に混ぜる仕組みです。
便利なんですが、企業のAI個人情報リスクが一気に上がりやすいポイントでもあります。
理由は2つ。
過剰共有とプロンプトインジェクションです。
RAGで一番最初に整えるべきは、AIより先に“社内データの置き場と権限”です。

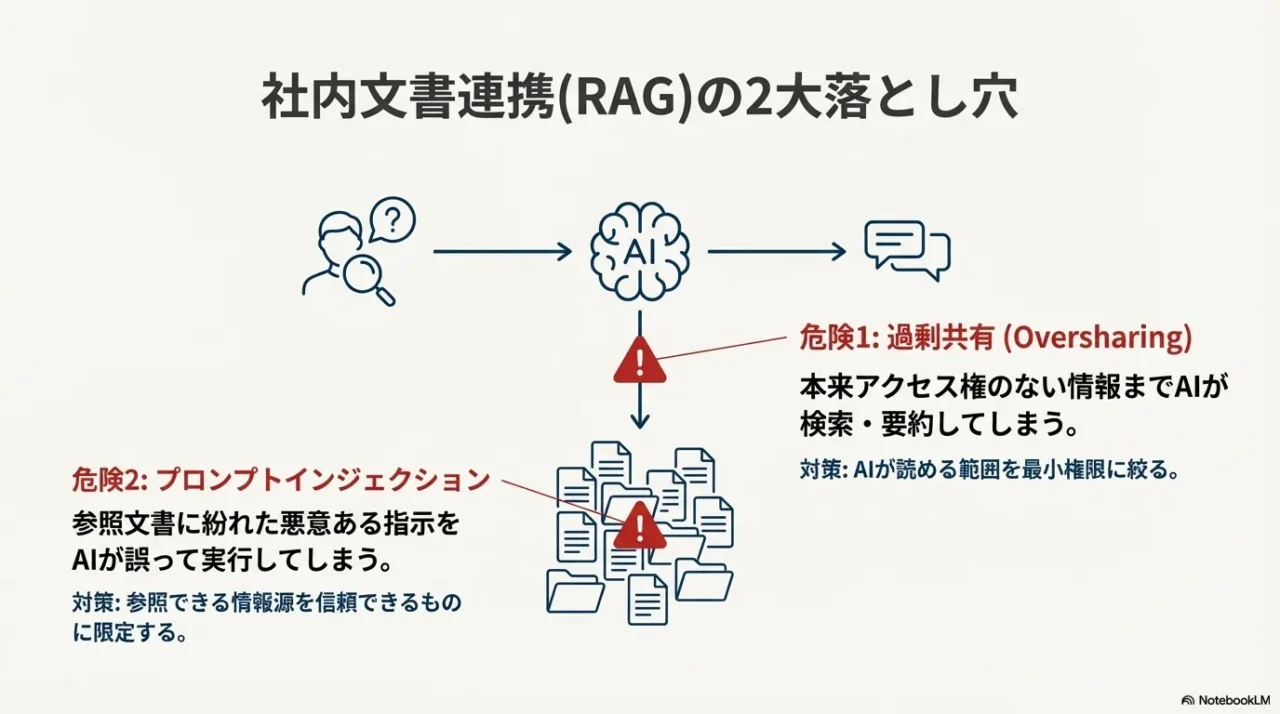
過剰共有(Oversharing)が一番多い
体感的にも、事故の多くはAIが勝手に盗むというより「そもそも権限が広すぎた」が原因です。
AIが入ると、検索と要約で“見つけやすく”なるので、結果的に漏えいのインパクトが増えます。
プロンプトインジェクションはRAGで現実になる
外部のWebや共有ドキュメントを参照する構成だと、文書の中に「この指示に従え」みたいな悪意ある文が混ざることがあります。
AIがそれを“指示”として誤解すると、意図しない情報を出したり、回答が汚染されたりします。
注意
RAGは「情報源が増えるほど強い」一方で、攻撃面も広がります。便利さの裏で、設計と運用の差が出ます。
私が押さえる最低限の対策
- 最小権限:AIが読める範囲を最小にする(部署・役割で分ける)
- 情報源のホワイトリスト:参照先を限定し、外部Webは慎重に
- 出力のガード:個人情報っぽい文字列を検知したら止める
- ログとレビュー:重要業務は人が最終確認する
議事録や要約ツールの運用で「共有設定の不備」が事故につながる話は、下の記事のセキュリティ章でも触れています。
RAG運用の考え方にも近いので、必要ならどうぞ。

RAGの設計で差がつくポイント
RAGって「検索して持ってきて答える」だけに見えるんですが、現場で事故が起きるのは、だいたい次のどれかです。
- 検索対象のドキュメントが広すぎて、意図せず個人情報が混ざる
- アクセス制御が甘く、権限外の情報が検索で出てしまう
- 外部データを混ぜた結果、悪意ある文章が混入して出力が汚染される
- キャッシュや共有リンクで、出力が別ルートに残る
よくある脅威と打ち手
| リスク | 起き方 | 打ち手 |
|---|---|---|
| 過剰共有 | 権限が広く、検索で出る | 最小権限、部署・役割で分離 |
| 意図しない混入 | 検索範囲が広い | 対象を絞る、タグ付け、情報分類 |
| プロンプトインジェクション | 外部文書の指示が混ざる | 外部参照を限定、無視ルール、フィルタ |
| 出力の二次流出 | 共有・転送・保存で拡散 | 共有手順の整備、監査ログ、レビュー |
RAGは上手く設計すると、社内の生産性が爆上がりします。
逆に、設計が甘いと情報漏えいの“加速装置”になります。
便利さを取りたいなら、最初に守りを固める。これが一番の近道です。
2-5. AIの個人情報リスク総まとめ
最後に、AIの個人情報リスクを最短で下げる結論をまとめます。
私は難しい議論より、まずこれで十分かなと思っています。
結論:事故を減らす3点セット

- 入れない:個人情報入力NG例(氏名・住所・連絡先・口座・ID/パスワード・身分証・医療/病歴)は原則入力しない
- 小さくする:マスキング・仮名化・抽象化でデータ最小化する
- 固める:企業は生成AI社内ルールテンプレ+DLP+権限設計(過剰共有対策)をセットで入れる
迷ったらこの“即決フロー”でOK
あなたが迷う場面って、だいたい「これ入れていいのかな?」ですよね。
私が推す即決フローはこれです。
- 個人が特定できるなら入れない
- 特定できなくても、漏れたら困るなら入れない
- 目的達成に必要なら、仮名化・要約・抽象化してから入れる
- それでも不安なら、専門家や社内窓口に相談してからにする
もし入力してしまったら
うっかりって、ゼロにはできないです。だから、転んだときの動きも決めておくと安心です。
- まずは共有しない(スクショ・転送・貼り付けを止める)
- 履歴や共有リンクがあるなら、削除・無効化を優先する
- 業務データなら、上長・情シス・法務に早めに相談する
- 再発防止として、禁止入力とマスク例を更新する
そして大事なことをもう一度。
AIサービスの仕様や契約条件は変わることがあります。
正確な情報は公式サイトをご確認ください。
最終的な判断は専門家にご相談ください。
ここまで読めば、あなたはもう「なんとなく怖い」から卒業できるはずです。
安全に使って、ちゃんと成果につなげていきましょう。














